Machine learning (ML) has significantly advanced in understanding and interacting with the world, driving progress in large-scale models such as large language models (LLMs), vision-language models (VLMs), robotics, and foundation models. However, as these systems are deployed in real-world applications, ensuring their reliability, trustworthiness, and interpretability remains a challenge. At LENS Lab, we focus on systematically analyzing, explaining, and improving ML-driven autonomous systems across these domains. Our research spans three core areas:
By tackling these challenges, we aim to create AI systems that are not only powerful but also transparent, accountable, and adaptable to real-world complexities.
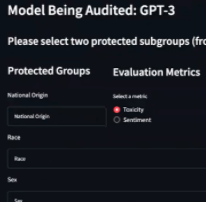
Large language models trained on extensive internet data often reflect biases and undesirable behaviors. We develop interactive AI auditing tools to systematically evaluate such models for discriminatory behaviors and toxic content generation in a human-in-the-loop fashion. Our tools provide summary reports highlighting vulnerabilities and biases against gender, race, and other protected attributes.
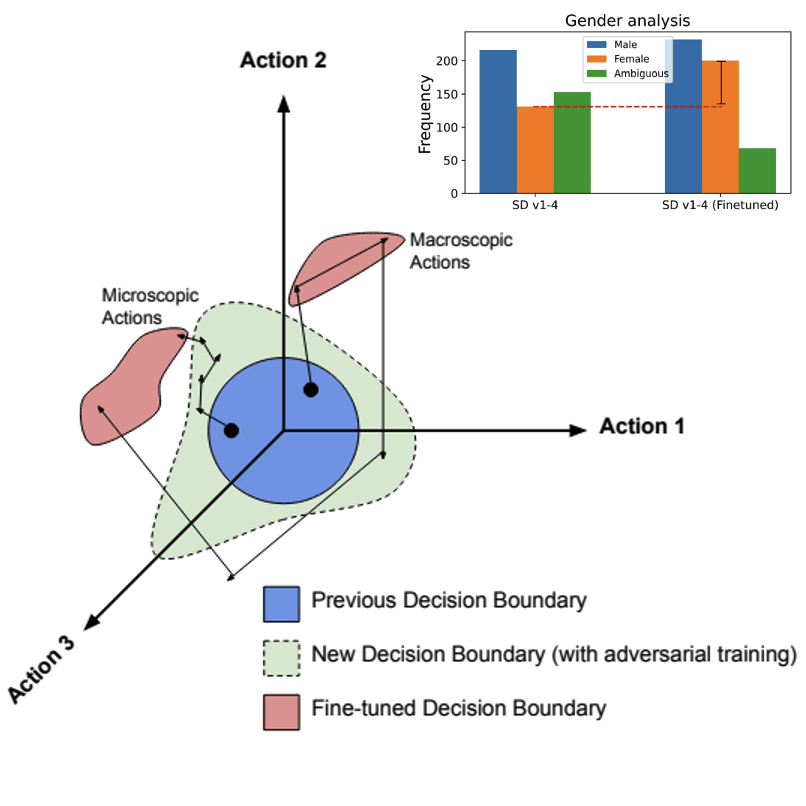
Foundation models often display unexpected failures due to their complex decision spaces. We use reinforcement learning (RL) strategies to systematically explore and identify critical failure modes. By optimizing reward functions to prioritize uncovering high-risk failures, our methods efficiently map potential weaknesses in models, enhancing their robustness.
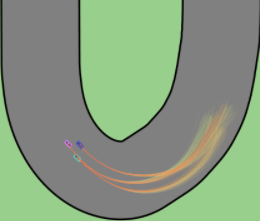
We investigate failure modes of autonomous vehicle perception systems under adverse weather conditions. Due to the complexity of deep learning-based perception modules, traditional exhaustive testing is impractical. Our reinforcement learning approach targets high-likelihood perception failures, particularly under varying rain conditions, allowing for improved safety and system reliability.
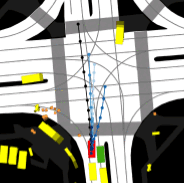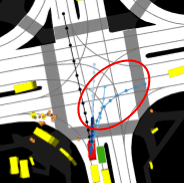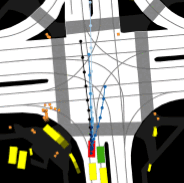
Deploying AI models in unfamiliar domains can lead to unexpected failures. Our research evaluates model robustness against domain shifts and adversarial inputs, enhancing reliability for medical image analysis, autonomous driving, and other critical applications.

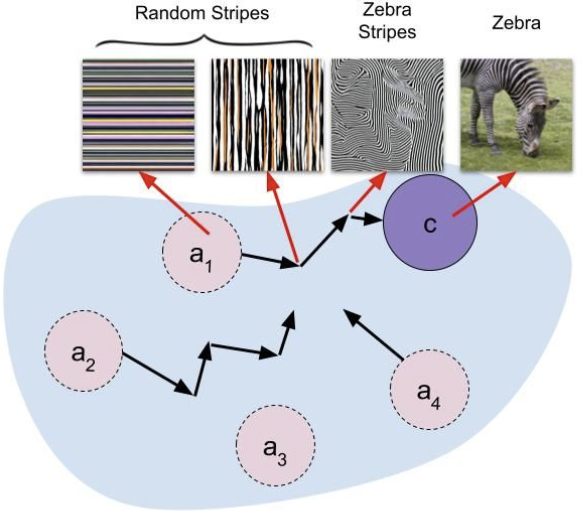
AI systems in robotics often operate as black boxes, obscuring the reasoning behind their decisions. Our research provides conceptual explanations to interpret complex neural network decisions in robotics, making their behavior understandable to end users and engineers. These explanations facilitate trust and effective debugging of autonomous systems.
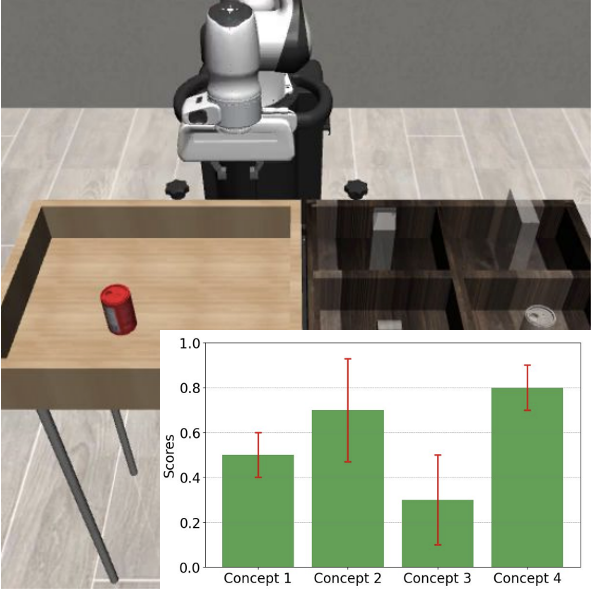
Vision-Language models (VLMs) integrate visual perception with linguistic understanding, yet often lack transparency in their decision-making processes. We address this by using preference learning methods to generate explainable concepts, enhancing interpretability and providing meaningful insights into model reasoning.
AI models frequently encounter scenarios outside their training distributions, leading to degraded performance. To enhance reliability, we develop adaptive domain generalization methods and efficient fine-tuning strategies that help models quickly adapt to new environments or tasks.
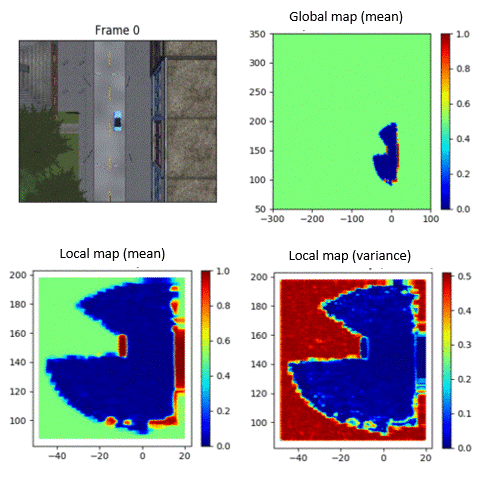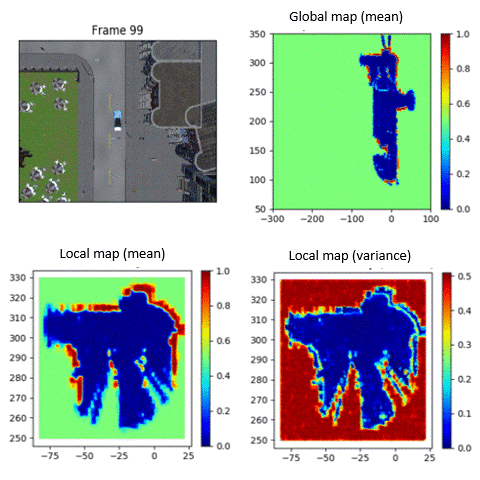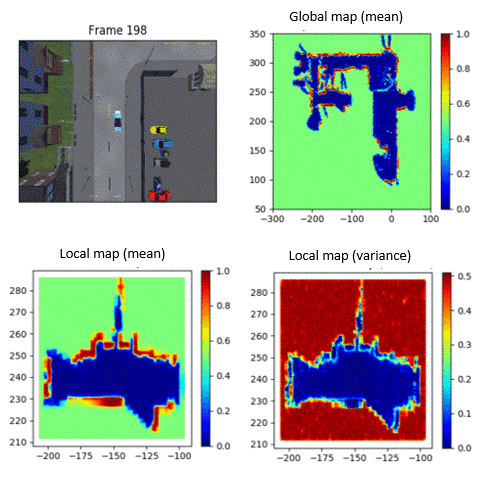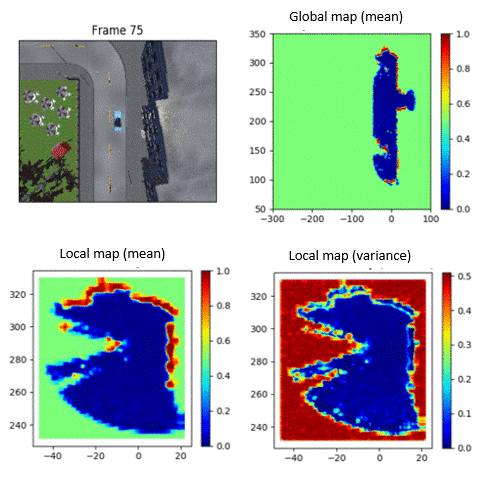
When AI systems fail, timely and effective recovery strategies are critical. Our research integrates reinforcement learning with real-time human feedback and automated preference learning to detect and quickly mitigate system failures, ensuring robust AI performance.